How transformer generate texts
decoding methods for language generation with Transformers
- Basic math: auto-regressive language generation
- Decoding methods
Basic math: auto-regressive language generation
auto-regressive language generation is based on the assumption that the probability distribution of a word sequence can be decomposed into the product of conditional next word distributions:
$$P\left(w_{1: T} \mid W_{0}\right)=\prod_{t=1}^{T} P\left(w_{t} \mid w_{1: t-1}, W_{0}\right)$$
- $W_0$: the context
- $T$: the length of word sequence
- it is determined
on-the-fly: when EOS token is generated.
- it is determined
Decoding methods
Currently, most prominent decoding methods are, mainly, Greedy search, Beam search, Top-K sampling and Top-p sampling.
Greedy Search
Definition
Given all previous words $w_{1: t-1}$ selects the word $w$ with the highest probability as its next word:
$$w_t = argmax_w P(w|w_{1:t-1})$$
Example
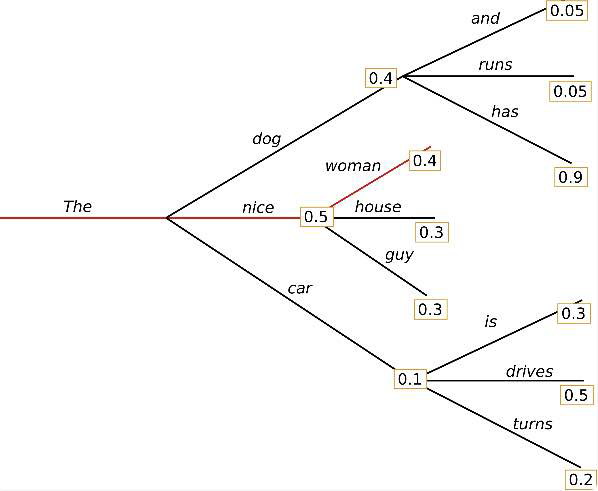
Starting from the word "The", the algorithm greedily chooses the next word of highest probability "nice" and so on, so that the final generated word sequence is ("The","nice","woman") having an overall probability of $0.5 \times 0.4 = 0.20.5×0.4=0.2$.
Feature
The major drawback is:
- Greedy Search may miss the sequence with overall highest probability.
- For example, a word “has” hidden behind a low probability word “dog”.
- beam search alleviate this problem
Beam Search
Definition
keeping num_beams the most-likely sequences, and eventually choosing the sequance with overall highest probability.
examplle
- num_beams = 2

Feature
- Beam search will always find an output sequence with higher probability than greedy search
- but is not guaranteed to find the most likely output.
Code
# activate beam search: set num_beams > 1
# early_stopping: generation is finished when all beam hypotheses reached the EOS token.
beam_output = model.generate(
input_ids,
max_length=50,
num_beams=5,
early_stopping=True
)
print("Output:\n" + 100 * '-')
print(tokenizer.decode(beam_output[0], skip_special_tokens=True))
Some function features of beam search
features:
-
no repeat n-gram
- no_repeat_ngram_size=2
-
multiple returns
- num_return_sequences
- num_return_sequences <= num_beams
-
the multiple beam output are only marginally different to each other.
- if increase diversity, trying increase beam number.
Why beam search might not be good in open-ended generation
-
Beam search work well in the case:
- length of desired generation is more or less fixed
-
Beam search does not work well in the case:
- output length can vary greatly: e.g. dialog and story generation
- beam search heavily suffers from repetitive generation
- beam search is “less surprising” than real-human’s answer

Sampling
sampling means randomly picking the next word $w_t$ according to its conditional probability distribution (conditioned on previous words $w_{1:t-1}$):
$$ w_{t} \sim P\left(w \mid w_{1: t-1}\right) $$
issue 1 with sampling: coherent
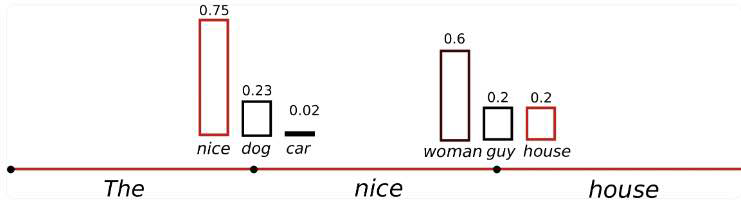
The first problem when sampling word sequences: The models often generate incoherent sentence.
A trick is to make the conditional distribution sharper (increasing the likelihood of high probability words and decreasing the likelihood of low probability words).
- by lowering the so-called temperature of the softmax.
- temperature increase: more randomness.
# set seed to reproduce results. Feel free to change the seed though to get different results
tf.random.set_seed(0)
# use temperature to decrease the sensitivity to low probability candidates
sample_output = model.generate(
input_ids,
do_sample=True,
max_length=50,
top_k=0,
temperature=0.7
)
print("Output:\n" + 100 * '-')
print(tokenizer.decode(sample_output[0], skip_special_tokens=True))
Top-K Sampling
In Top-K sampling, the K most likely next words are filtered and the probability mass is redistributed among only those K next words
An example
set K= 6: we limit our sampling pool to 6 words.

# set seed to reproduce results. Feel free to change the seed though to get different results
tf.random.set_seed(0)
# set top_k to 50
sample_output = model.generate(
input_ids,
do_sample=True,
max_length=50,
top_k=50
)
print("Output:\n" + 100 * '-')
print(tokenizer.decode(sample_output[0], skip_special_tokens=True))
Good and Bad
Good of Top-K sampling:
- may success in story generation, filter out weird words
Bad:
- when we have sharp distribution from beginning,
- limiting the sample pool to a fixed size K could endanger the model to produce gibberish sentence
- limit the model’s creativity
Top-p (nucleus) sampling — revised top-k sampling
chooses from the smallest possible set of words whose cumulative probability exceeds the probability p.
- set a probability threshold that you want
an example

# set seed to reproduce results. Feel free to change the seed though to get different results
tf.random.set_seed(0)
# deactivate top_k sampling and sample only from 92% most likely words
sample_output = model.generate(
input_ids,
do_sample=True,
max_length=50,
top_p=0.92,
top_k=0
)
print("Output:\n" + 100 * '-')
print(tokenizer.decode(sample_output[0], skip_special_tokens=True))
Top-K + Top-P
Top-p can also be used in combination with Top-K, which can:
- avoid very low ranked words
- while allowing for some dynamic selection.
# set seed to reproduce results. Feel free to change the seed though to get different results
tf.random.set_seed(0)
# set top_k = 50 and set top_p = 0.95 and num_return_sequences = 3
# to get multiple independently sampled outputs, we can again set the parameter num_return_sequences > 1:
sample_outputs = model.generate(
input_ids,
do_sample=True,
max_length=50,
top_k=50,
top_p=0.95,
num_return_sequences=3
)
print("Output:\n" + 100 * '-')
for i, sample_output in enumerate(sample_outputs):
print("{}: {}".format(i, tokenizer.decode(sample_output, skip_special_tokens=True)))
Reference:
- https://huggingface.co/blog/how-to-generate
- transformers.generation_utils.GenerationMixin.generate