Use Multiple GPUs
Single Machine Data Parallel
When data is too large to feed in a single GPU
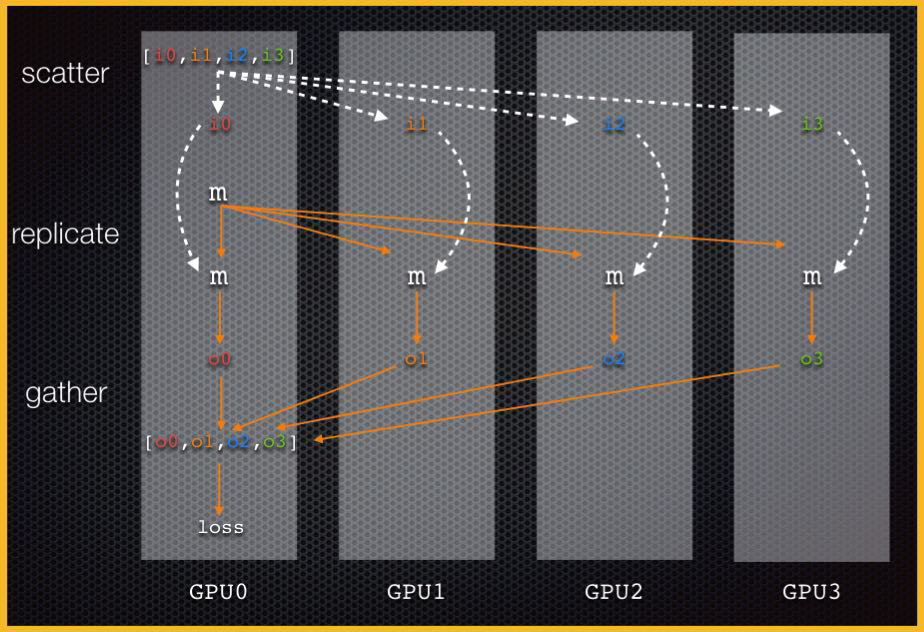
- data is scatterred across GPUs
- Model is replicated on each GPUs
- Pytorch Gather the ouput from each GPUs,
- and compute loss, gradient, updates weights
Code is simple, just one line:
model = Net().to("cuda:0")
model = torch.nn.DataParallel(model) # add this line
# normal Training loops ...
Single Machine Model Parallel
When Model itself is too large to fit in the memory of a single GPU
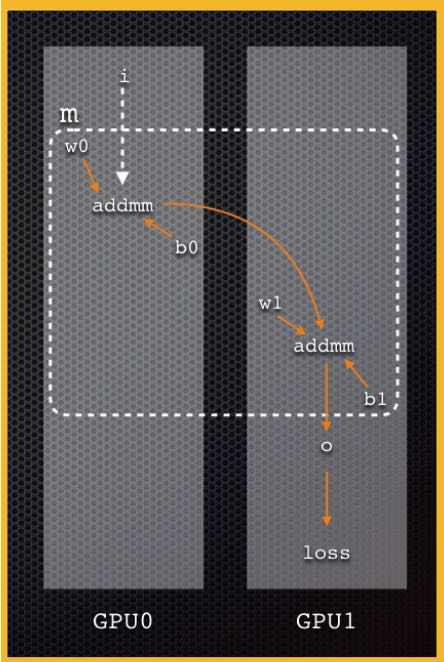
- data is sent to GPU 0
- process 1 is processed in GPU 0
- data is sent to GPU 1
- process 2 is processed in GPU 1
- Output is computed
- data comes in on GPU 0, but output on GPU 1
Code:
Require manually transfer the data inside the nn module self-defined.
class Net(torch.nn.Module):
def __init__(self, *gpus):
super().__init__(self)
self.gpu0 = torch.device(gpus[0]) # pass gpu to a nn.module constructer
self.gpu1 = torch.device(gpus[1])
self.sub_net1 = torch.nn.Linear(10, 10).to(self.gpu0) self.sub_net2 = torch.nn.Linear(10, 5).to(self.gpu1)
def forward(self, x):
y = self.sub_net1(x.to(self.gpu0))
z = self.sub_net2(y.to(self.gpu1)) # blocking return z
model = Net("cuda:0", "cuda:1") # training loop...
- pass gpu to a
nn.moduleconstructer - save each operation(layer) to corresponding GPUs In forward:
- manually transfer data across GPUs
Distributed Data Parallel
- GPUs across all machines receives different data, process in parallel at the same time.
- backward update the gradient across al GPUs
Code:
def one_machine(machine_rank, world_size, backend):
torch.distributed.init_process_group(
backend, rank=machine_rank, world_size=world_size
)
gpus = {
0: [0, 1],
1: [2, 3],
}[machine_rank] # or one gpu per process to avoid Global Interpreter Lock
model = Net().to(gpus[0]) # default to first gpu on machine
model = torch.nn.parallel.DDP(model, device_ids=gpus)
# training loop...
for machine_rank in range(world_size):
torch.multiprocessing.spawn(
one_machine, args=(world_size, backend),
nprocs=world_size, join=True # blocking
)
Distrobuted Model and Data Parellel
Multiple Machines, each has Multiple GPUs

def one_machine(machine_rank, world_size, backend):
torch.distributed.init_process_group(backend, rank=machine_rank, world_size=world_size )
gpus = {
0: [0, 1],
1: [2, 3],
}[machine_rank]
model = Net(gpus)
model = torch.nn.parallel.DDP(model) # training loop...
for machine_rank in range(world_size):
torch.multiprocessing.spawn(
one_machine, args=(world_size, backend), nprocs=world_size, join=True
)
Summary
If data and model can fit in a single GPU:
- Parellel is not a concern since traininig in a single GPU is the most efficient way
If there’re multiple GPUs on your server, and wanna speed up training with minimum code change:xs
Single-machine Multi-GPU DataParrellel
If there’re multiple GPUs on your server, and wanna speed up training. And are willing to write a little more code:
Single-machine multi-GPU Distributed Data Parallel
Break the machine boundary…